¿Os habéis preguntado alguna vez qué es lo que hace que un jugador de fútbol sea portero, defensa, centrocampista o delantero? ¿Existe(n) alguna(s) característica(s) de su juego que definen su rol dentro del equipo? Estas son las preguntas que me planteé hace unas semanas mientras recopilaba, transformaba y limpiaba los datos de la 2018 FIFA World Cup Russia.
Fruto de ese análisis, publiqué estos dos artículos: 16 datos y 20 datos más. En estas publicaciones analizaba datos sobre distancia recorrida, tiempo de juego y velocidad de los jugadores en los 64 partidos de la fase final del pasado mundial.
En el artículo de hoy voy a utilizar esa misma información para, a través de un par de algoritmos de machine learning (aprendizaje automático), responder a las dos preguntas iniciales.
Como lo que tengo es una colección de jugadores etiquetados (ya sé a priori si tal jugador es delantero, portero, defensa o centrocampista), me he decantado por dos algoritmos de aprendizaje supervisado: knn y árboles de decisión. En ambos casos, separamos nuestra colección inicial en una muestra de entrenamiento (train) y en una de prueba (test). Enseñamos al ordenador con los datos de entrenamiento y evaluamos su aprendizaje con los datos de test.
Para poder interpretar bien los resultados, os dejo la leyenda de la FIFA para las posiciones de los jugadores:
- DF: defender – defensa.
- FW: forwarder – delantero.
- GK: goalkeeper – portero.
- MF: midfielder – centrocampista.
Prueba número 1 – knn con 10 variables:
Dispongo de las siguientes variables (10) de los 603 jugadores que saltaron al césped en el mundial:
- Distancia total recorrida.
- Tiempo total de juego.
- Tiempo total en la zona Z1 (0 – 7 km/h).
- Tiempo total en la zona Z2 (7 – 15 km/h).
- Tiempo total en la zona Z3 (15 – 20 km/h).
- Tiempo total en la zona Z4 (20 – 25 km/h).
- Tiempo total en la zona Z5 (>25 km/h).
- Velocidad máxima.
- Velocidad media
- Número de sprints.
El resultado del algoritmo knn es una tasa de acierto del 52,94%. No es para tirar cohetes. Vemos la matriz de confusión para ver dónde acierta y dónde falla.

Con los porteros lo clava; con los defensas regular; con los delanteros mal y con los centrocampistas regular.
Parece claro que el comportamiento de los porteros se parece muy poco al de los jugadores de campo. Creo que a nadie le sorprende. ¿Probamos con un árbol de decisión?
Prueba número 2 – árbol de decisión con 10 variables:
Las variables son las misma que para la prueba número 1. Este es el árbol resultante:

La precisión es del 58,82%. ¿Lo interpretamos? Este árbol de decisión nos divide a los jugadores en 4 grupos utilizando solo 2 de las variables que teníamos en nuestro set de datos:
- Si la velocidad media es mayor o igual a 4 km/h y menor que 6,1 km/h –> Defensa. Acierto del 66%.
- Si la velocidad media es menor que 4 km/h –> Portero. Acierto del 100%.
- Si la velocidad media es mayor o igual que 6,1 km/h y el tiempo en la zona Z5 es mayor o igual que 3,5 segundos –> Delantero. Acierto del 46%.
- Si la velocidad media es mayor o igual que 6,1 km/h y el tiempo en la zona Z5 es menor que 3,5 segundos –> Centrocampista. Acierto del 66%.
Los resultados son algo mejores pero tampoco para tirar cohetes. ¿Qué puedo hacer para mejorar estos resultados? Varias cosas:
- Aumentar el número de observaciones. En este caso, disponer de datos de más jugadores. Me tendría que ir a recoger datos de más mundiales o bien desagregar los datos y utilizar como observación los datos de cada partido jugado por cada jugador.
- Aumentar el número de variables, o sustituir algunas de las existentes por otras. Voy a tirar por esta vía.
Prueba número 3 – knn con 19 variables:
A las 10 variables que ya teníamos, les añadimos estas 9 nuevas:
- Goles.
- Asistencias.
- Paradas.
- Disparos a puerta.
- Tarjetas amarillas.
- Tarjetas rojas directas.
- Tarjetas rojas indirectas.
- Faltas cometidas.
- Faltas recibidas.
El resultado del algoritmo knn es una tasa de acierto del 63,87%. Mejoramos la tasa de la prueba 1 pero el valor sigue siendo bajo. Vemos la matriz de confusión para ver dónde acierta y dónde falla.

Con los porteros lo sigue clavando; con los defensas regular tirando a bien; con los delanteros regular y con los centrocampistas regular.
Prueba número 4 – árbol de decisión con 19 variables:
Las variables son las misma que para la prueba número 3. Este es el árbol resultante:
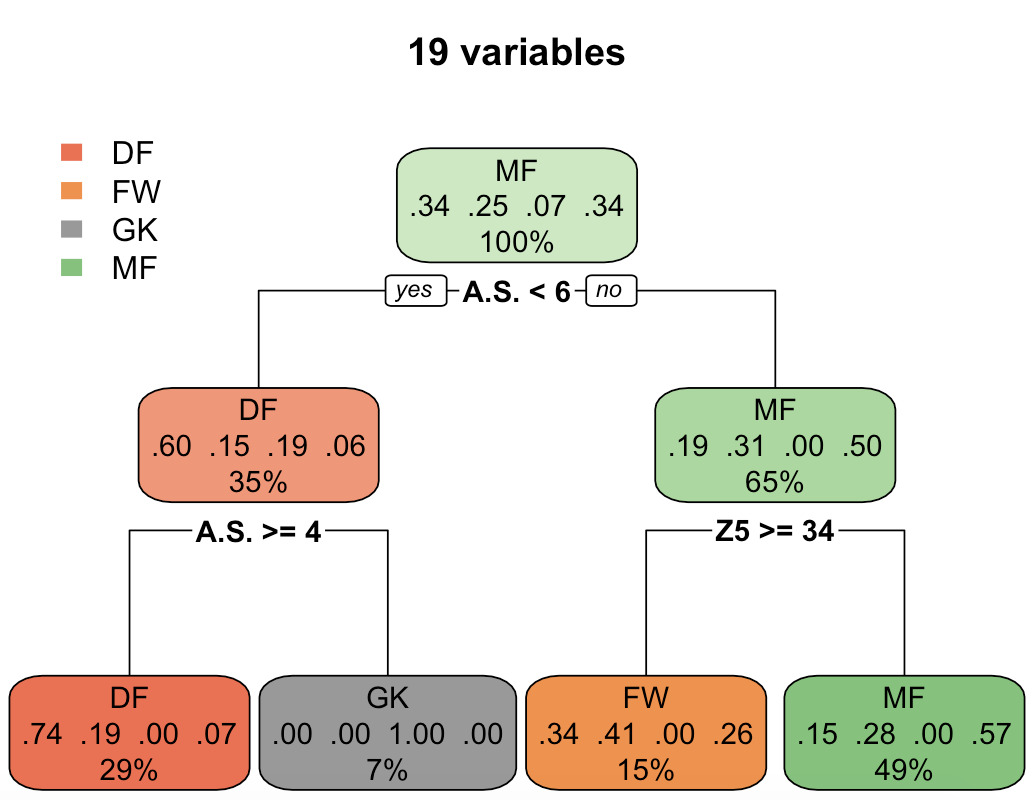
La precisión es del 61,30%. ¿Lo interpretamos? Este árbol de decisión nos divide a los jugadores en 4 grupos utilizando solo 2 de las variables que teníamos en nuestro set de datos (las mismas que antes):
- Si la velocidad media es mayor o igual a 4 km/h y menor que 6 km/h –> Defensa. Acierto del 74%.
- Si la velocidad media es menor que 4 km/h –> Portero. Acierto del 100%.
- Si la velocidad media es mayor o igual que 6 km/h y el tiempo en la zona Z5 es mayor o igual que 34 segundos –> Delantero. Acierto del 41%.
- Si la velocidad media es mayor o igual que 6 km/h y el tiempo en la zona Z5 es menor que 34 segundos –> Centrocampista. Acierto del 57%.
Los resultados no mejoran. ¿Qué puedo hacer para mejorar estos resultados?
Prueba número 5 – modifico algunas variables:
Se me ocurre modificar las variables relativas a las zonas de juego y ponerlas en forma de porcentajes sobre el tiempo total de juego en lugar de en términos absolutos (segundos). No obtenemos ninguna mejora.
Prueba número 6 – árbol de decisión con 19 variables y sin jugadores con menos de 90 minutos jugados:
En el set de datos hay una serie de jugadores con muy pocos minutos jugados. Entiendo que podemos tratarlos como outliers en el sentido en que sus datos pueden no ser representativos debido al poco tiempo de juego. Elimino a estos 120 jugadores y hago el nuevo árbol de decisión:
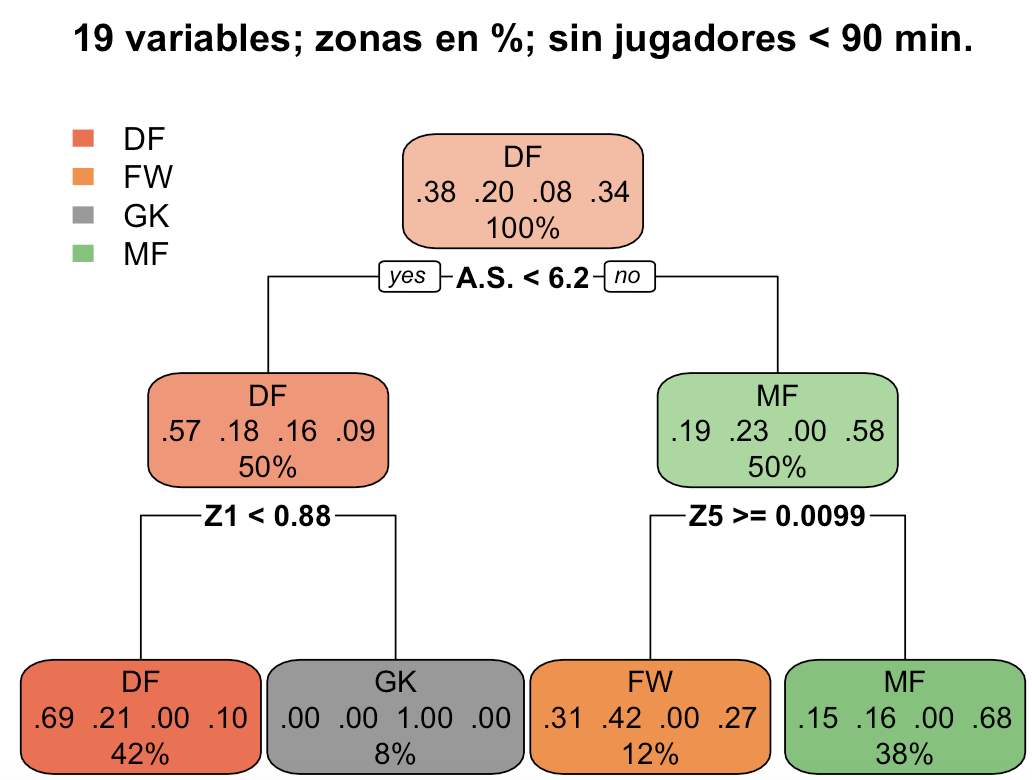
La precisión es del 68,40%, superior a los anteriores pero no excesivamente fiable. Sin embargo, una nueva variable entra en juego. ¿Lo interpretamos? Este árbol de decisión nos divide a los jugadores en 4 grupos utilizando solo 3 de las variables que teníamos en nuestro set de datos:
- Si la velocidad media es menor que 6,2 km/h y el tiempo en la zona Z1 es menor que el 88% del tiempo total de juego –> Defensa. Acierto del 69%.
- Si la velocidad media es menor que 6,2 km/h y el tiempo en la zona Z1 es mayor o igual que el 88% del tiempo total de juego –> Portero. Acierto del 100%.
- Si la velocidad media es mayor o igual que 6,2 km/h y el tiempo en la zona Z5 es mayor o igual que el 0,99% del tiempo total de juego –> Delantero. Acierto del 42%.
- Si la velocidad media es mayor o igual que 6,2 km/h y el tiempo en la zona Z5 es menor que el 0,99% del tiempo total de juego –> Centrocampista. Acierto del 68%.
Conclusiones:
- Las variables velocidad media y porcentaje del tiempo en la zona Z1 nos permiten diferenciar a los porteros de los jugadores de campo.
- No disponemos de las variables adecuadas para poder clasificar de manera más certera a los jugadores de campo (defensas, centrocampistas y delanteros).
¿Probamos con algún algoritmo no supervisado? ¿Qué 4 grupos nos saldrán?
El algoritmo kmeans no ofrece mejores resultados que los dos anteriores (knn y árboles de decisión). De hecho, su tasa de acierto se sitúa entre el 40 y el 45%. Nuevamente, los porteros se retratan muy bien y muy diferenciados de lso jugadores de campo pero los jugadores de campo aparecen entremezclados en los otros 3 grupos.

Quizás existen más variables “absolutas” que no tienen demasiado sentido. Pruebo a relativizarlas en función del tiempo uy a eliminar del estudio las variables “distancia total recorrida) y “tiempo total de juego”.
No obtenemos ninguna mejora significativa. Debo probar otra vía
¿Qué está pasando? ¿Puedo hacer algo más? Sí, puedo probar una tercera vía, que consiste en quitar los outliers (sujetos que se comportan de manera anómala) antes de aplicar los algoritmos. De hecho, podría ocurrir que, por ejemplo, algunos defensas se estuvieran comportando como centrocampistas y estuviéramos “engañando” a nuestro clasificador.
Separo nuestra muestra de futbolistas en 4 muestras, una por cada tipo de jugador y compruebo si existen comportamientos anómalos (outliers) dentro de cada grupo.
Defensas: 184 jugadores
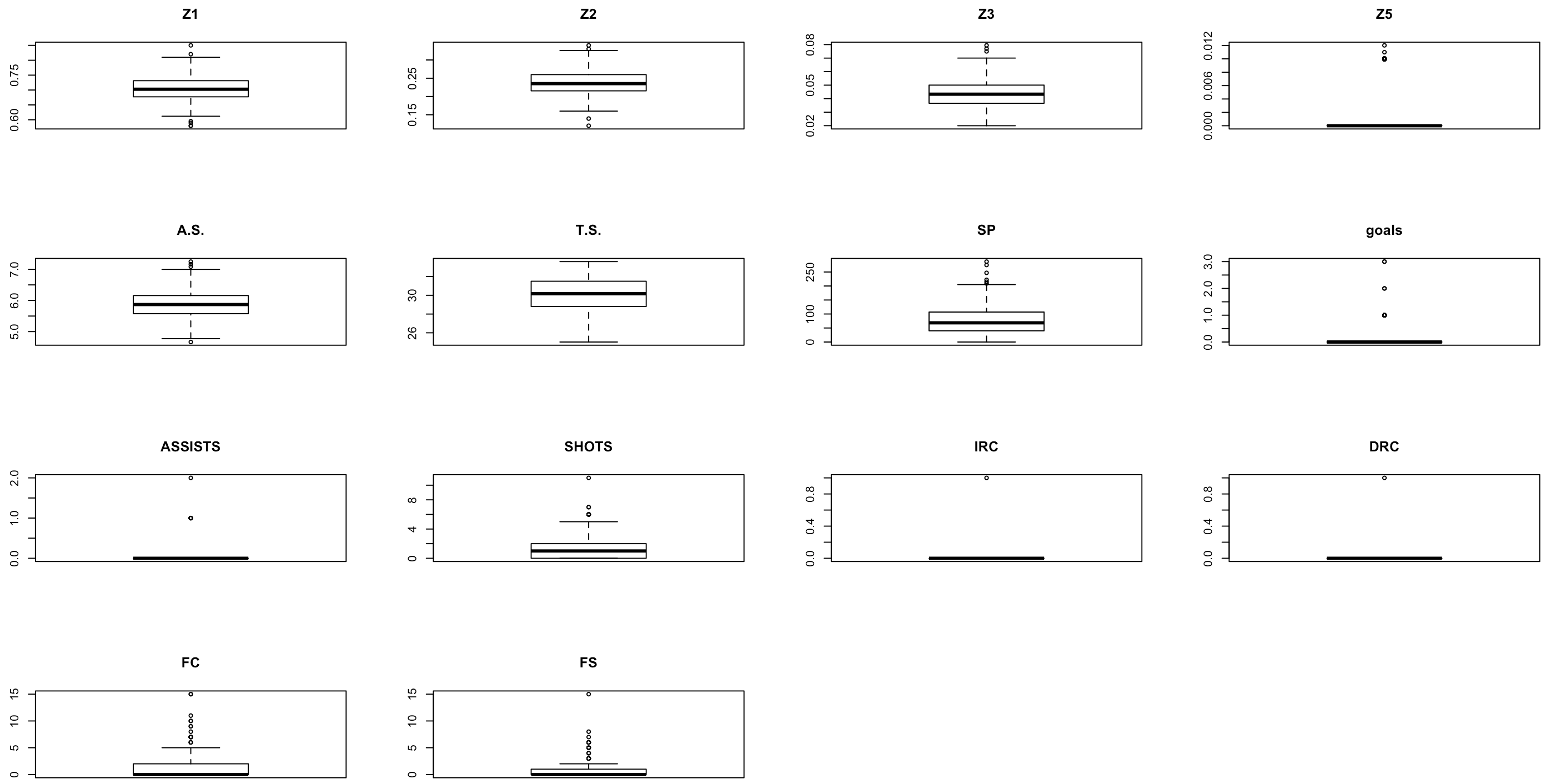
Los circulitos representan valores anómalos. Ojo, no son valores erróneos sino valores que se escapan (por exceso o por defecto) del comportamiento “normal” del grupo (en este caso, de los defensas). Por ejemplo, es anómalo que un defensa meta 1, 2 o 3 goles. La gran mayoría de los defensas que han participado en el mundial no han metido ningún gol.
Si eliminamos a aquellos defensas que presentan valores anómalos, podremos obtener una muestra representativa fiel del comportamiento de un defensa. Si repetimos este mismo procedimiento con los 4 grupos de jugadores, tendremos la muestra completa para enseñar a nuestro clasificador. Corremos el riesgo de quedarnos con muy pocas observaciones.
Prueba número 7 – árbol de decisión con 13 variables y sin jugadores sin menos de 90 minutos jugados:
Pruebo con nuevas variables, esta vez relacionadas con la posición de los jugadores en el terreno de juego. A las 10 variables de las pruebas número 1 y número 2, añado estas tres variables:
- Tiempo jugado en campo rival (O.H. de opposite half).
- Tiempo jugado en el tercio de ataque (A.3rd).
- tiempo jugado en el área contraria (P.A. de penalty area).
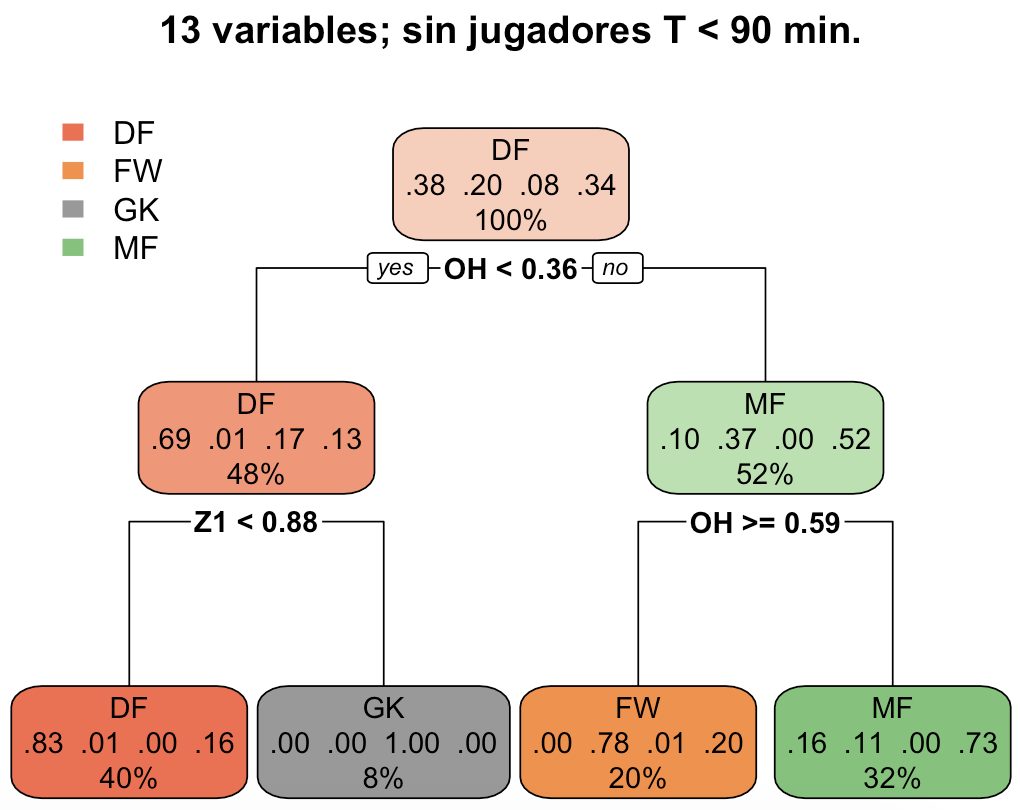
Hemos conseguido elevar la precisión hasta el 78,95%. Ya estamos en una zona aceptable ¿Lo interpretamos? Este árbol de decisión nos divide a los jugadores en 4 grupos utilizando solo 2 de las variables que teníamos en nuestro set de datos:
- Si el tiempo de juego en su propio campo es menor que el 36% del tiempo de juego total y el tiempo de juego en la zona de velocidad Z1 es menor que el 88% del tiempo total de juego –> Defensa. Acierto del 83%.
- Si el tiempo de juego en su propio campo es menor que el 36% del tiempo de juego total y el tiempo de juego en la zona de velocidad Z1 es mayor o igual que el 88% del tiempo total de juego –> Portero. Acierto del 100%.
- Si el tiempo de juego en su propio campo es mayor o igual que el 59% del tiempo de juego total –> Delantero. Acierto del 78%.
- Si el tiempo de juego en su propio campo es mayor o igual que el 36% del tiempo de juego total y menor que el 59% del tiempo de juego total –> Centrocampista. Acierto del 73%.
Creo que la vía de las variables se ha agotado y la única forma de mejorar los porcentajes y la precisión es haciéndome con más datos de juego otros mundiales y/o eurocopas para contar con más observaciones.
Si alguno dispone de estos datos sobre mundiales y/o eurocopas, le agradecería la colaboración.
Otra opción, que voy a explorar en otro artículo es considerar como observación, cada partido de cada jugador en lugar de agrupar todos los partidos de un mismo jugador en una única observación. ¿Mejorará el resultado?
¿Qué jugadores no se han comportado de acuerdo a lo que cabría esperar de ellos en función de su posición a priori? próximamente.
To be continued…
#data #bigdata #datascience #futbol #football #soccer #fifa #fifaworldcup #russia2018 #datascientist #rstudio #tableau #bigdata #final #russia2018 #footballanalytics #footballdata #goalkeeper #defender #midfielder #forwarder #portero #defensa #centrocampista #delantero #machinelearning #inteligenciaartificial #aprendizajeautomatico #arbolesdedecision #decisiontrees #knn #vecinomascercano #aprendizajesupervisado #aprendizajenosupervisado #kmeans
One Comment
Pingback: