En un artículo anterior os daba alguna pista sobre cómo mejorar vuestras opciones de éxito en juegos como “La Ruleta de la Suerte” o “El ahorcado“. Primero estudiábamos el peso de cada una de las 27 letras presentes en la ortografía del español. Luego, afinábamos nuestras posibilidades un poco más añadiendo la variable “número de caracteres” al estudio. Esto es, veíamos el peso de cada carácter en función del número de caracteres que tuviera la palabra o palabras a adivinar.
En esta nueva entrega pretendo dar un paso de gigante, un salto cualitativo de la mano de las reglas de asociación. En minería de datos y aprendizaje automático (machine learning), las reglas de asociación se utilizan para descubrir hechos que ocurren en común dentro de un determinado conjunto de datos. Esta metodología ha resultado muy exitosa para descubrir relaciones entre variables en grandes conjuntos de datos.
Las reglas de asociación presentan muchas aplicaciones en la gran distribución, donde sirven como base para tomar decisiones sobre marketing como precios promocionales para ciertos productos o dónde ubicar éstos dentro del supermercado. Una regla de asociación de un supermercado tendría una forma parecida a esta:

Y viene a representar que, el consumidor que compra cebollas y vegetales (verduras), muy probablemente también comprará carne. No es magia, ni sentido común, es un análisis de cientos, miles, millones de tickets de la compra.
¿No es justamente esto lo que buscamos? ¿No sería maravilloso disponer de una tabla donde, partiendo de una serie de letras ya conocidas (lado izquierdo de la ecuación), obtuviéramos el lado derecho, esto es, las letras más probables o con mayor confianza?
En nuestro caso, cada palabra del lemario es un ticket de la compra y cada carácter (letra) es un producto de los 27 posibles. Entonces, nuestras reglas de asociación serían del estilo:

- lhs: representa el lado izquierdo. “Si…”
- rhs: representa el lado derecho: “… entonces…”
- support: el respaldo que tiene la regla. En este caso, el número de veces que “q” aparece en mis tickets. q aparece un 3,5% de las veces.
- confidence: la probabilidad de que una palabra que contiene la letra “q”, contenga también la letra “u”. En este caso, el 100%. Una apuesta segura.
- lift: estadístico que compara la frecuencia observada de una regla con la frecuencia esperada simplemente por azar (si la regla no existe realmente). Cuanto más se aleje el valor de lift de 1, más evidencias de que la regla no se debe a un artefacto aleatorio, es decir, mayor la evidencia de que la regla representa un patrón real.
- count: número de apariciones de “q” en términos absolutos.
Para este nuevo análisis, los preparativos de los datos nos son tan triviales como lo eran para los anteriores. Yo me he valido del software RStudio y de una buena dosis de paciencia. En concreto, he utilizado la librería arules para los cálculos y la librería arulesviz para las representaciones. Haciendo uso de las reglas “a priori”, estas son las 15 reglas con mayor confianza:

Y estas son las 15 reglas con mayor soporte:
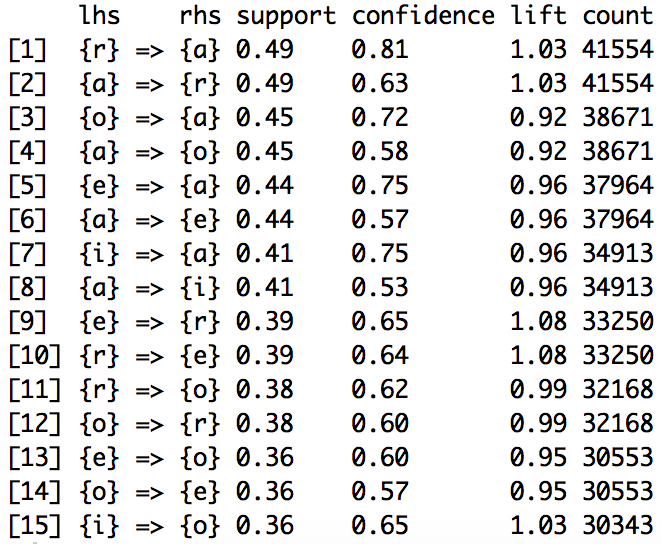
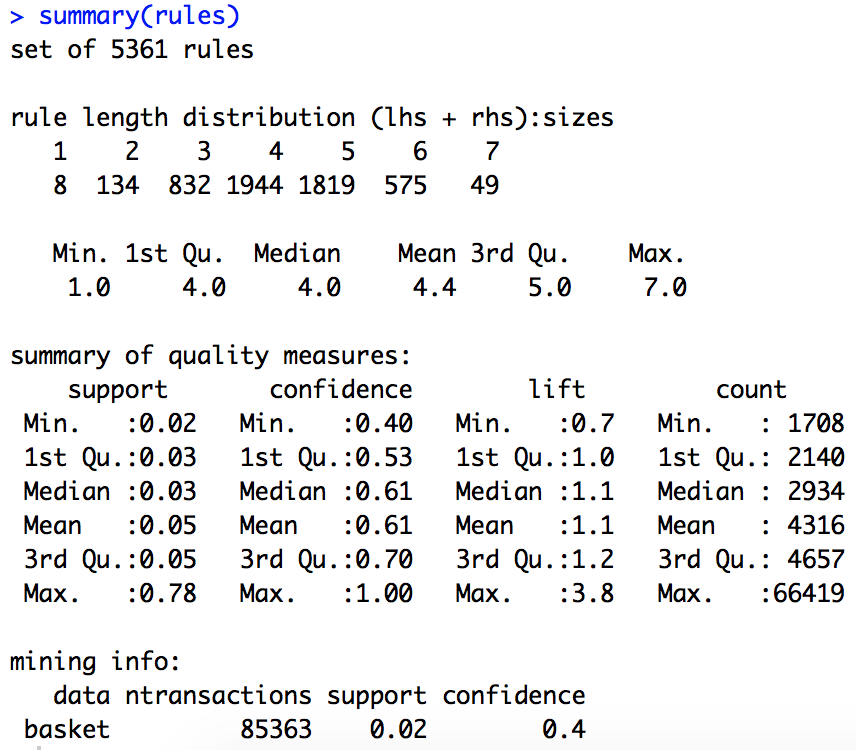
Al ejecutar el algoritmo “a priori“, obtenemos 5.361 reglas, la mayoría de ellas formadas por 4 elementos (parte izquierda + parte derecha). Las transacciones (palabras) tenidas en cuenta han sido 85.363.
De forma gráfica, así quedan representadas las 5.361 reglas en función del respaldo (support) y la confianza (confidence):

Todavía podríamos afinar un poco más nuestras reglas, conociendo el número de letras de la palabra, tal y como proponíamos en el artículo anterior.
Viendo la distribución de las palabras por número de caracteres, vamos a quedarnos con las de 8 caracteres para confeccionar reglas de asociación:

Estas son las 15 reglas con más confianza:

Y estas las 15 reglas con mayor soporte:

¿Y si eliminamos las vocales? ¿Y si…? Como veis, un mundo de posibilidades por explorar. Si alguno está pensando en ir a “La Ruleta de la Suerte” o bien no quiere perder al “Ahorcado”, que me escriba y ¡preparamos una chuleta!
#data #datascience #datascientist #textmining #mineriadetextos #rstudio #bigdata #letras #palabras #words #bigdata #tableau