Decisiones de negocio.
Aunque mi día a día profesional esté fuertemente vinculado con los datos y con los números, nunca debemos dejar de lado el contexto de “negocio” en el que trabajamos.
Sobre todo, al comienzo y al final de todo proceso de minería de datos. Al comienzo para comprender el negocio: plantear las preguntas que queremos responder y buscar los datos para hacerlo o ver qué preguntas podemos responder con los datos que ya tenemos. Y, al final, para saber interpretar y evaluar los resultados de nuestro proceso.
La semana pasada, en el contexto de un curso de Machine Learning que estoy impartiendo, estaba explicando los algoritmos de clasificación a mis alumnos. Y llegó el momento de mediar la bondad de dichos algoritmos. En concreto, les expliqué la matriz de confusión para un clasificador binario.
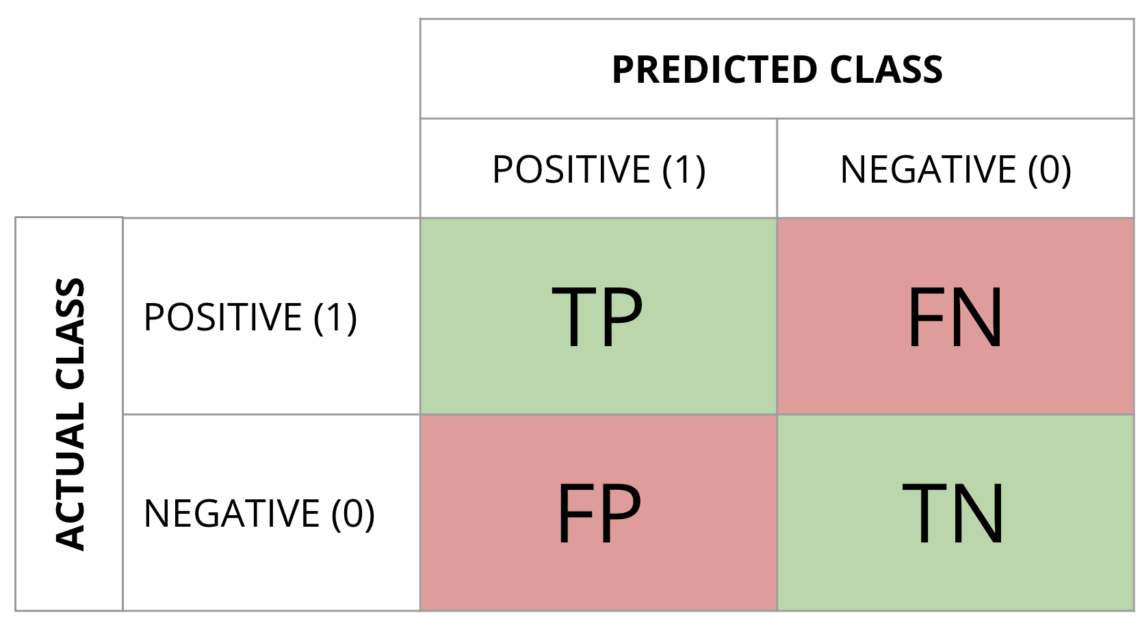
La Matriz de confusión representa los 4 tipos de sucesos que pueden ocurrir al ejecutar un modelo:
- El sistema predice “Clase 0” y la salida correcta es “Clase 0”.
- El sistema predice “Clase 1” y la salida correcta es “Clase 0”.
- El sistema predice “Clase 0” y la salida correcta es “Clase 1”.
- El sistema predice “Clase 1” y la salida correcta es “Clase 1”.
La precisión (accuracy)
La forma más inmediata de medir la bondad de un clasificador es calcular su porcentaje de aciertos: sucesos acertados / número total de sucesos.
Accuracy = (TP+TN) / (TP+FN+FP+TN)
Ante esta definición, les hacía las siguientes dos preguntas que os lanzo también a vosotros:
- ¿Valen lo mismo los TP y los TN?
- ¿Valen lo mismo los FP y los FN?
Ya os adelanto que la respuesta suele ser NO.
Se lo ilustraba con estos 3 ejemplos.
Ejemplo #1: esta es la salida de un clasificador que intenta predecir el fallo de una máquina con la ayuda de una serie de variables predictoras.
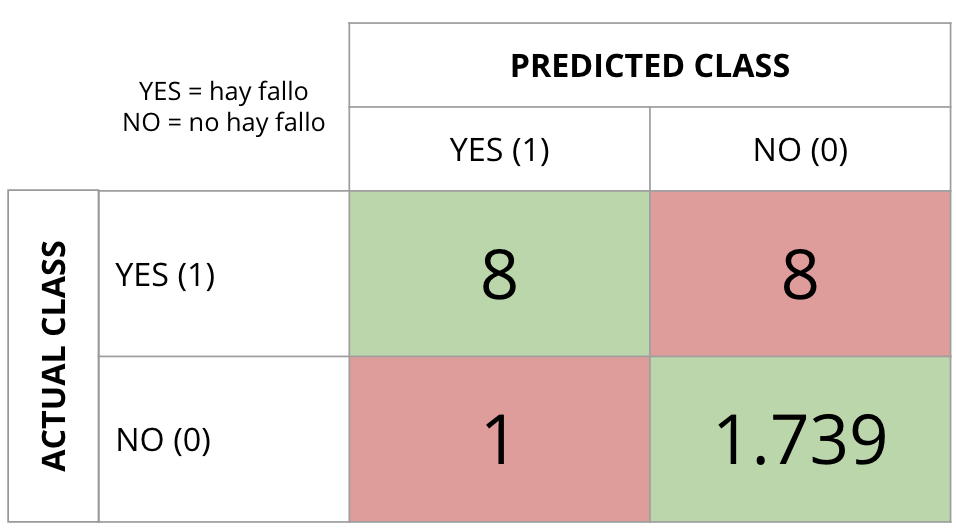
¿Qué os parece?
Si calculamos la precisión, obtenemos un 99%. Aciertos: 1.739 + 8 = 1.747. Sucesos totales: 1.756. Vamos, que nuestro clasificador acierta en el 99% de los casos. No está nada mal, ¿no?. Ahora bien, si analizamos la tabla en detalle, ¿qué tal predecimos los fallos? Había 16 síes en mi dataset de prueba (test) y el modelo ha sido capaz de predecir 8 –> 50%. Ummmm, esto (recall o sensitivity) ya no me gusta tanto. Por otro lado, de todos los que predigo como fallos, el 88% (8/9) lo son. Otro buen dato (Positive Predictive Value).
En un caso como estos, lo que me interesa es que no se me escape ningún fallo. Por lo tanto, la precisión no es lo único en lo que debo fijarme.
El resultado es fruto de un acusado desbalanceo de clases que no fue corregido para que los alumnos vieran la importancia del balanceo para este algoritmo.
Ejemplo #2: obtenemos un modelo (clasificador) que intenta predecir si un paciente está enfermo o no.
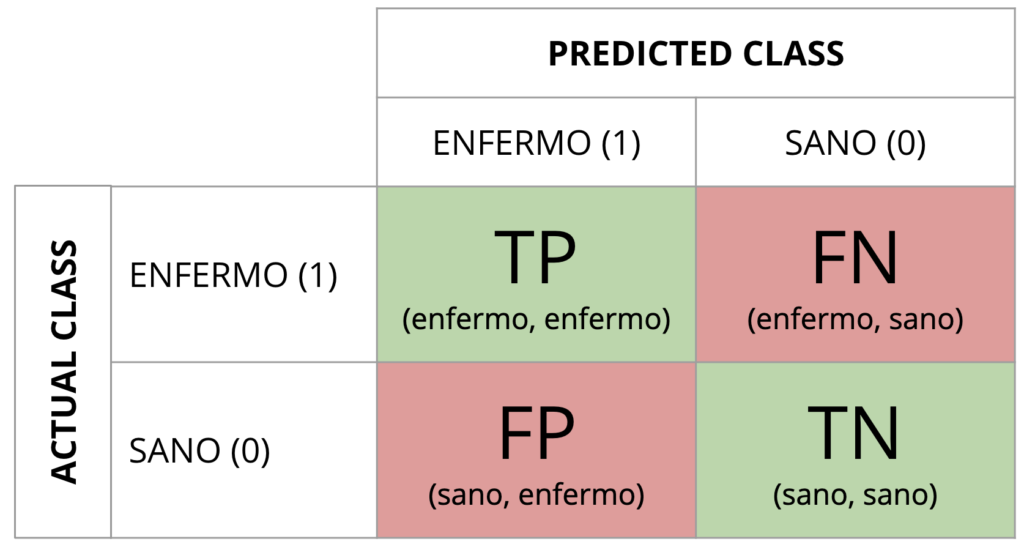
La pregunta que les lanzo es… ¿qué error penaliza más? ¿Decirle a un paciente sano que está enfermo? ¿O decirle a un paciente enfermo que está sano? Decirle a un paciente enfermo que está sano puede conllevar que no se trate la enfermedad y que los síntomas se agraven y que, incluso, sea demasiado tarde para tratarse en el futuro. En caso contrario, estamos dando un disgusto a un paciente durante un período de tiempo. Mi opinión es que, en este caso, lo importante es evitar los falsos negativos.
Ejemplo #3: obtenemos un modelo (clasificador) que intenta predecir si un acusado es culpable o inocente.
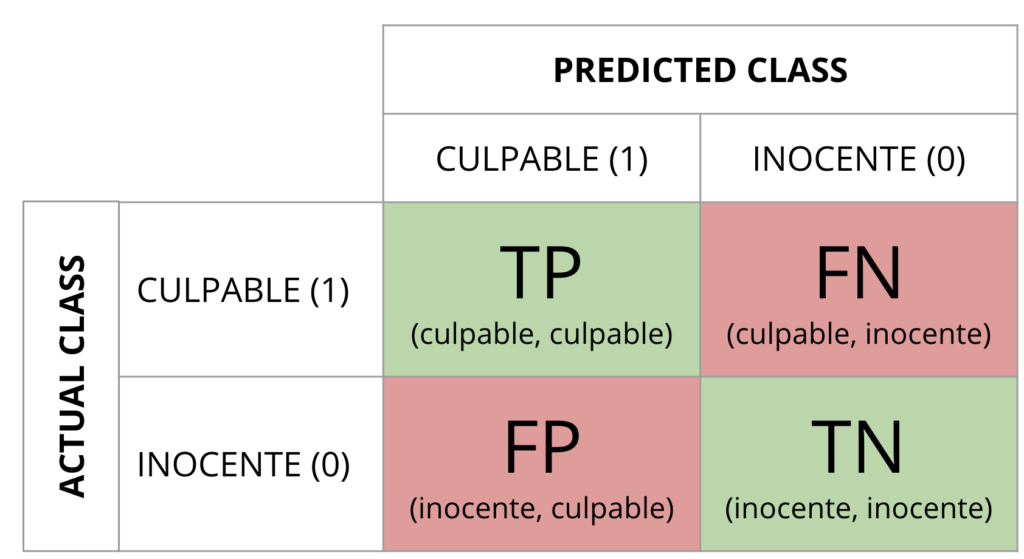
La pregunta que les lanzo es… ¿qué error penaliza más? ¿Liberar a un culpable? ¿O meter en la cárcel a un inocente? Hagan juego.
Con esto intento hacerles ver que los modelos y los algoritmos son importantes, mucho. Pero no menos importante son las decisiones de negocio y el contexto de los datos. Por no hablar de lo “pesado” que soy con lo importantes que son los datos con los que construimos nuestro modelo.
Hasta pronto.
Datacy – data driven decisions.

