Escribo estas líneas el 26 de julio de 2024 a escasas horas de que comience la competición en los Juegos Olímpicos de Paris. La ceremonia inaugural será el viernes 26 pero la acción empieza hoy mismo. Y, ya que estamos y antes de sumergirnos en datos, vamos a aclarar 2 conceptos: juegos olímpicos y olimpiada. Los Juegos Olímpicos son un…
-
-
Curiosidades meteorológicas Donostia – Junio 2024
-
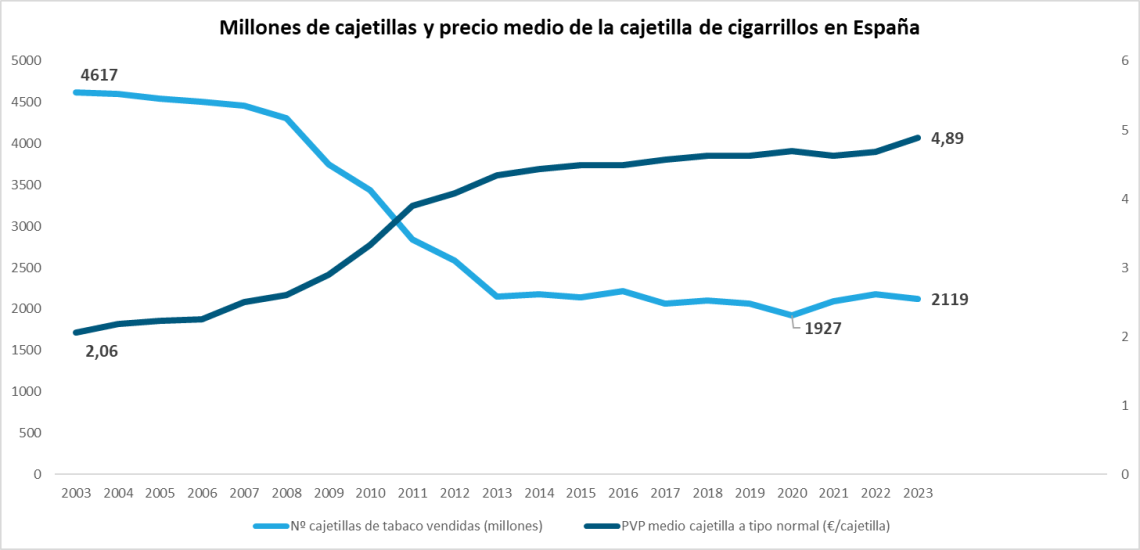
No corren buenos tiempos para el tabaco… ¿o sí?
Hoy hablamos de venta de tabaco, con datos de la Agencia Tributaria que es quién se encarga de recaudar los impuestos. Recordemos que el tabaco, al igual que las bebidas alcohólicas, los hidrocarburos y algunos pocos productos más, están sujetos a impuestos especiales (II.EE.) más allá del propio IVA. La unidad de medida va a ser la cajetilla de tabaco;…
-
Curiosidades meteorológicas Donostia – Mayo 2024
-
La comida que tiramos
Hoy os traigo datos tristes; datos malos; datos que deberían hacernos reflexionar. SOn datos relacionados con el desperdicio alimentario en los hogares españoles. Son datos de 2022 (no he encontrado valores para 2023… y ya estamos e mayo). Fuente de datos: MAPA (Ministerio de Agricultura, Pesca y Alimentación) e INE. Datos globales Dato #1: los hogares españoles desperdiciaron durante el…
-
Curiosidades meteorológicas Donostia – Abril 2024
-
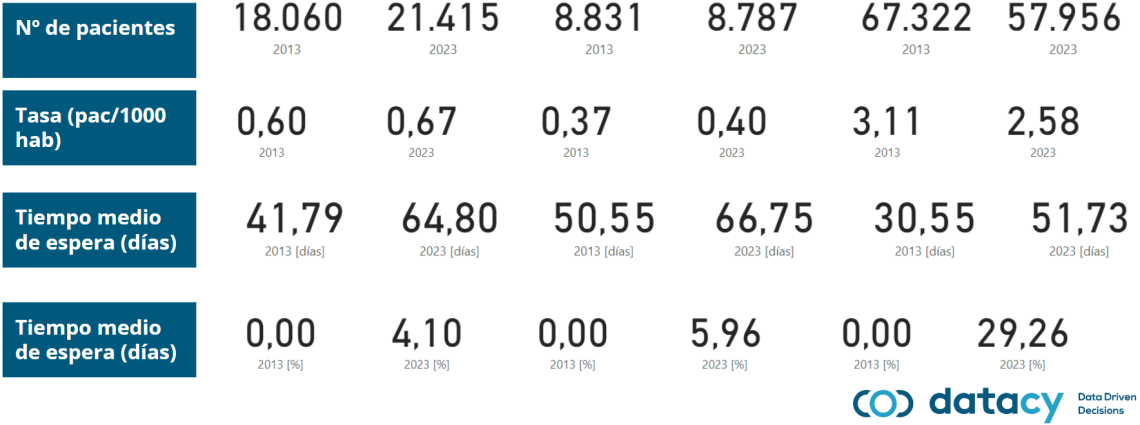
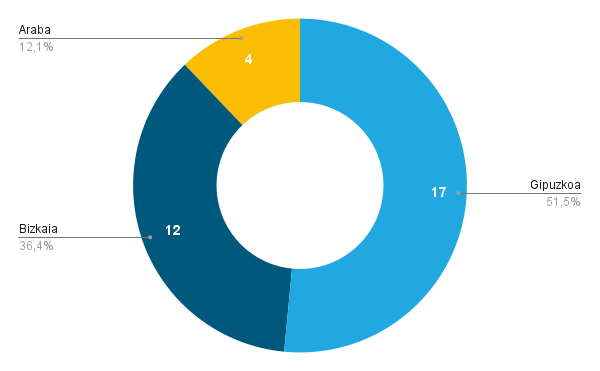
¿Qué pasa con los juanetes?
Esta semana se han publicado los datos de las listas de espera en la Sanidad Pública en España en 2023. El nombre técnico del informe es: SISTEMA DE INFORMACIÓN SOBRE LISTAS DE ESPERA EN EL SISTEMA NACIONAL DE SALUD (SISLE – SNS) y está accesible en la página Web del Ministerio de Sanidad. He descargado los datos, los he pasado…
-
Curiosidades meteorológicas Donostia – Marzo 2024
-
¿Coche o email?
Hoy nos toca reflexionar. Reflexionar con datos, claro. Todo surge a raíz de la lectura del décimo informe Data Never Sleeps. Un informe que se representa en forma de infografía y nos da una idea de lo que ocurre en Internet cada 60 segundos. Cada minuto. Ocurren muchas cosas. ¿Demasiadas? Os dejo algunas cifras: 6,3M de búsquedas en Google. 694k…
-
Curiosidades meteorológicas Donostia – Febrero 2024