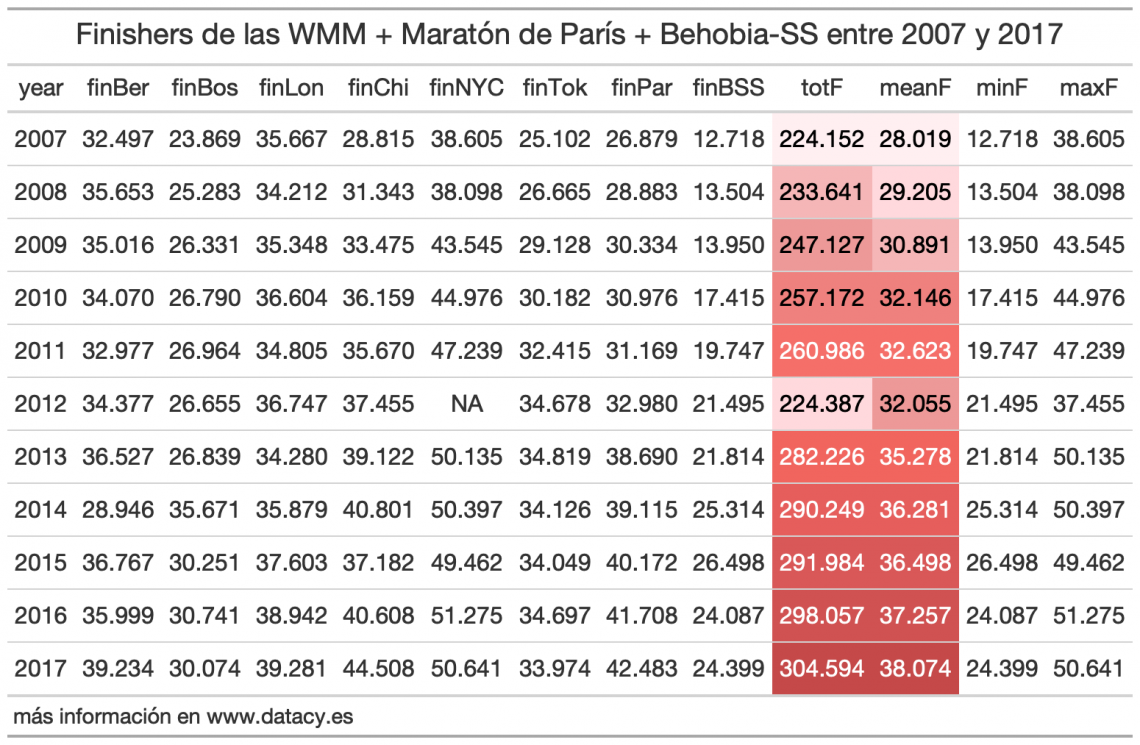
La sencillez y la versatilidad del paquete dplyr me han cautivado desde que descubrí esto de la ciencia de datos. Encadenar operaciones mediante el operador pipeline (%>%) permite crear un código secuencial, ordenado y fácil de interpretar. Además, nos permite no tener que repetir en nombre del dataframe o del tibble sobre el que queremos aplicar la operación. dplyr pertenece…