La sencillez y la versatilidad del paquete dplyr me han cautivado desde que descubrí esto de la ciencia de datos. Encadenar operaciones mediante el operador pipeline (%>%) permite crear un código secuencial, ordenado y fácil de interpretar. Además, nos permite no tener que repetir en nombre del dataframe o del tibble sobre el que queremos aplicar la operación.
dplyr pertenece a una colección de paquetes de R llamada tidyverse. Esta familia está compuesta por:
- dplyr.
- tidyr
- ggplot2.
- readr.
- tibble.
- purrr.
Si utilizáis R para leer, importar, transformar, manipular o analizar datos, apuesto a que al menos el 90% de vuestro código está creado con funciones de estos paquetes.
Trabajando por filas
dplyr, y R en general, son particularmente adecuados para realizar operaciones sobre columnas, y realizar operaciones sobre filas es mucho menos intuitivo. Operaciones tan triviales como calcular un mínimo, un máximo, una suma o una media “por filas” pueden resultar latosas.
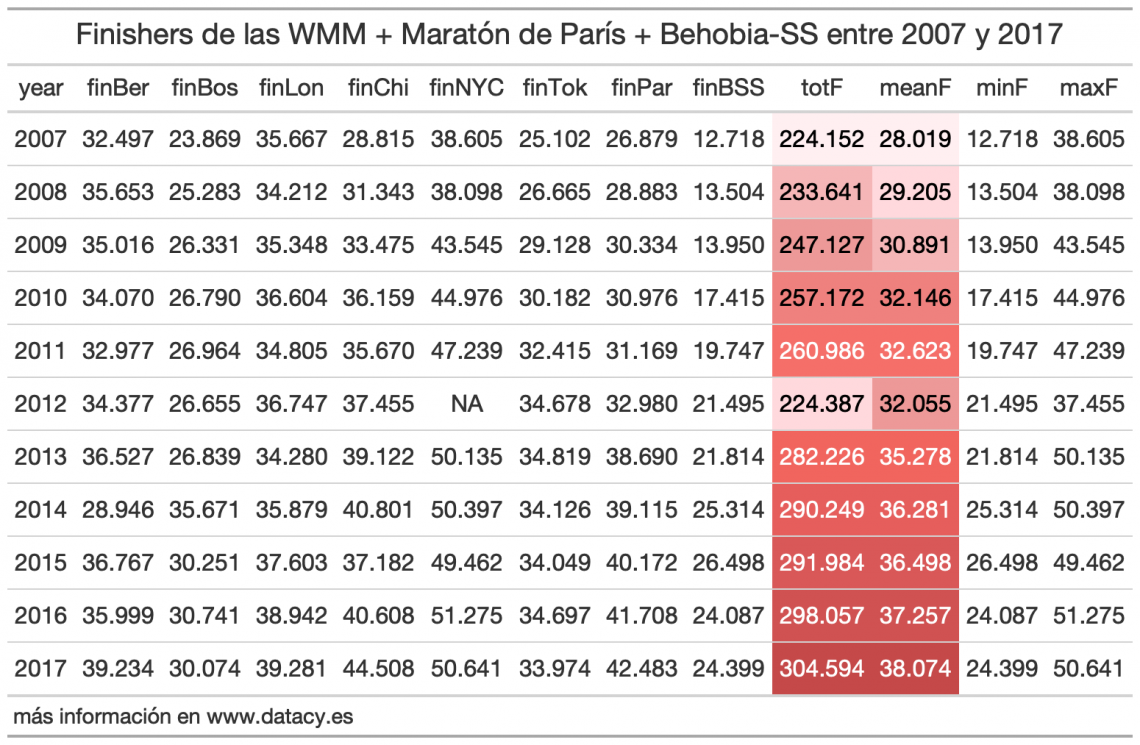
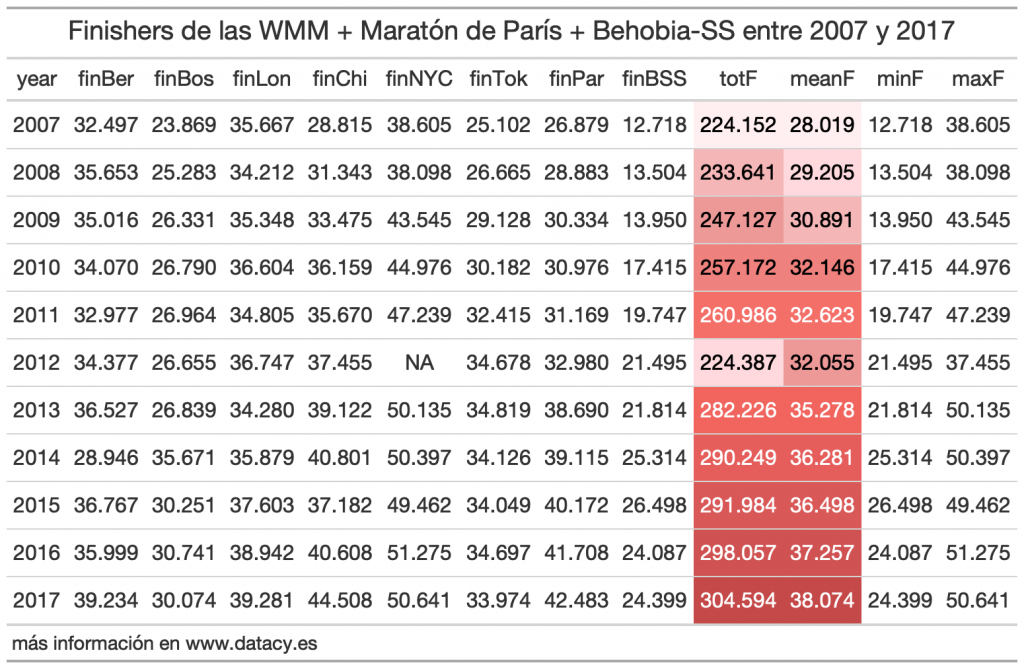
Vamos con una pequeña colección de datos que creé para un estudio sobre el boom del running. Incluye a los finishers de las 6 World Maraton Majors (NYC, London, Chicago, Berlin, Tokyo y Boston) más París y la Behobia – San sebastián.
Vamos a calcular, por año (por fila, vaya):
- El total de finishers.
- La media de finishers.
- El mínimo de finishers.
- El máximo de finishers.
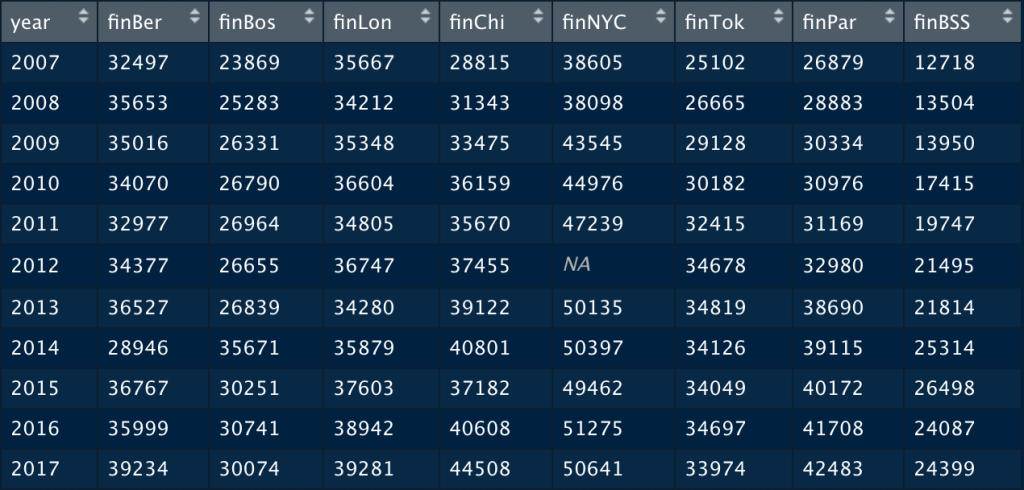
Sin Rowwise()
Acudimos a dplyr y calculamos las nuevas columnas con la función mutate y con las operaciones correspondientes del paquete base.
rBoomRes <- rBoomRes %>%
dplyr::mutate(totF = sum(finBer, finBos, finLon, finChi, finNYC, finTok, finPar, finBSS, na.rm = TRUE),
meanF = mean(c(finBer, finBos, finLon, finChi, finNYC, finTok, finPar, finBSS), na.rm = TRUE),
minF = min(finBer, finBos, finLon, finChi, finNYC, finTok, finPar, finBSS, na.rm = TRUE),
maxF = max(finBer, finBos, finLon, finChi, finNYC, finTok, finPar, finBSS, na.rm = TRUE))
Este es el resultado:
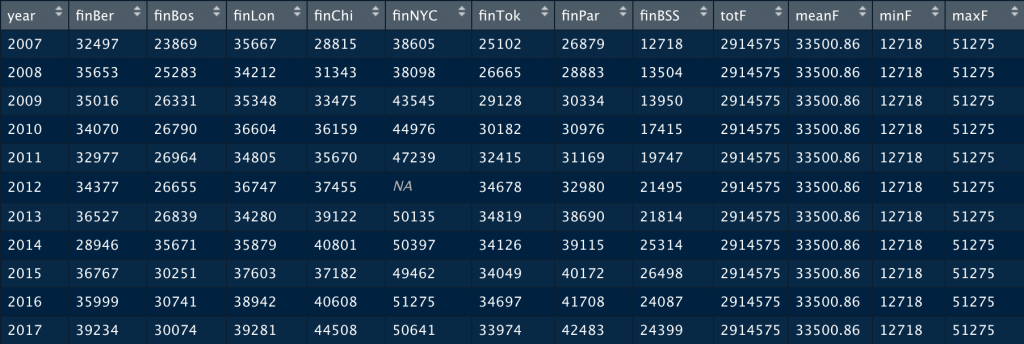
Ummmm, no tiene muy buena pinta. Lo que R nos ofrece es una suma de todos los datos de todas filas, el valor mínimo entre los valores de las columnas de todas las filas, etc. Esto es, no está trabajando fila a fila.
Con Rowwise()
Podemos solucionar el problema anterior con tan solo añadir una nueva línea a nuestro código:
rBoomRes <- rBoomRes %>%
dplyr::rowwise() %>%
dplyr::mutate(totF = sum(finBer, finBos, finLon, finChi, finNYC, finTok, finPar, finBSS, na.rm = TRUE),
meanF = mean(c(finBer, finBos, finLon, finChi, finNYC, finTok, finPar, finBSS), na.rm = TRUE),
minF = min(finBer, finBos, finLon, finChi, finNYC, finTok, finPar, finBSS, na.rm = TRUE),
maxF = max(finBer, finBos, finLon, finChi, finNYC, finTok, finPar, finBSS, na.rm = TRUE))
Con el siguiente resultado:
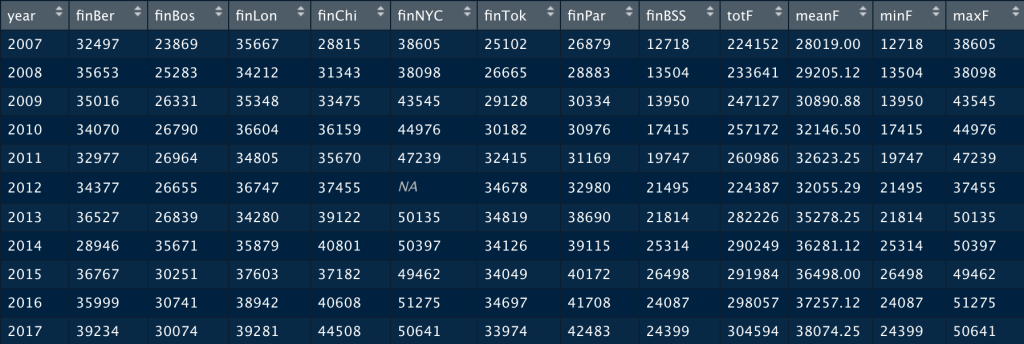
Por último, os dejo el resultado de aplicar un poco de formateo a la tabla anterior con el paquete gt del que os hablé en otra ocasión.
¡Hasta pronto!
datacy – data driven decisions

