Cuando trabajamos con datos, es frecuente que realizemos la misma operación sobre varias columnas de un mismo data frame. Copiar y pegar ahorra tiempo pero puede ser fuente de errores (descuidos).
Hoy os presento una de las nuevas funcionalidades de uno de mis paquetes favoritos (dplyr). Dplyr pertenece a la colección de paquetes tidyverse, de uso obligado en esto de la manipulación de datos en R.
Dplyr 1.0.0 está disponible en CRAN desde el pasado 1 de junio.
Hasta ahora…
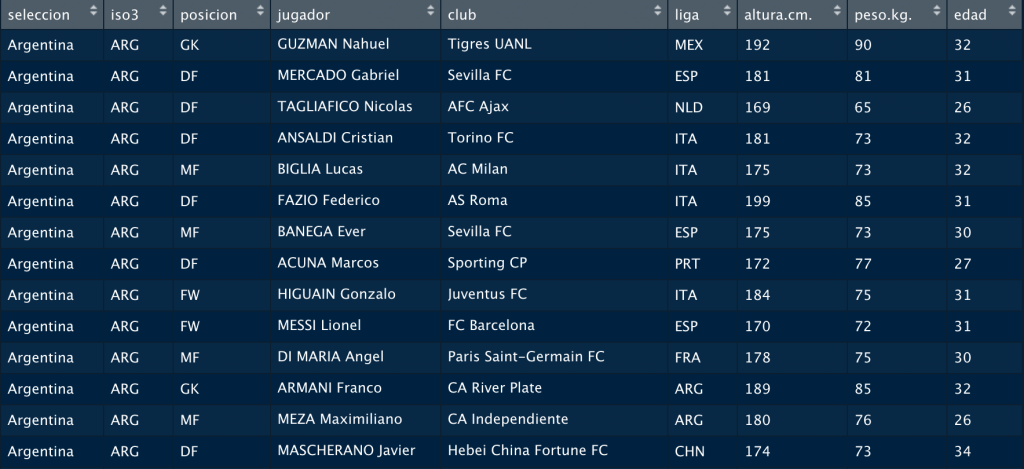
Imaginemos un data frame como el de la siguiente imagen sobre el que queremos calcular el peso medio y la altura media de los jugadores de cada club.
Hasta la aparición de across(), mi forma de abordar el problema era la siguiente:

Como véis, por cada variable sobre la que queremos aplicar una función (la media en este caso), necesitamos una línea de código.
Across al rescate
La función across viene a nuestro rescate cuando queremos aplicar la misma función a varias columnas.
El mismo resumen anterior podemos obtenerlo con estas líneas de código:

Ummm, nos hemos ahorrado una línea. No parece gran cosa pero, ¿y si tenemos unas cuántas variables y queremos aplicar más de una función sobre ellas?
Vamos a calcular el mínimo, el máximo y la media de las mismas ds variables anteriores:
Forma tradicional de trabajo

Las líneas de código creen muy rápido.
Nueva forma de trabajo con la función across()

La diferencia, ahora sí, es más notable.
Aún podemos aumentar un poco más la productividad si queremos aplicar dichas funciones sobre, por ejemplo) todas las variables numéricas del data frame:

Bienvenida a la familia tidyverse, across().
Podéis descargar el código utilizado en este enlace.
datacy – data driven decisions