
Hoy os traigo otra perlita de dplyr para los que os gusta (o no os queda más remedio) que manipular datos.
Si la semana pasada os mostraba cómo mejorar vuestra productividad con la función across(), hoy os voy a mostrar cómo ordenar columnas en un data frame sin necesidad de aprenderos los índices y/o realizar anotaciones adicionales en un cuaderno. Todo gracias a relocate().
datos
Para el desarrollo de este post voy a trabajar con una data frame que contiene información pública de la FIFA sobre los jugadores que participaron en la FIFA World Cup Russia 2018.
Tiene la siguiente estructura:
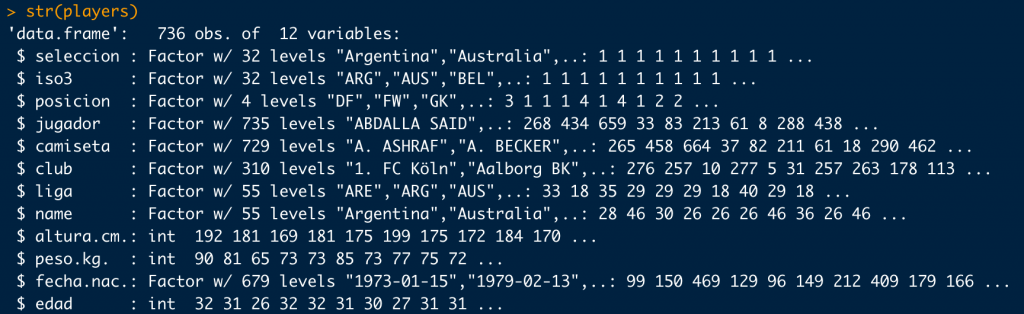
Hasta ahora siempre me he apañado con expresiones como esta para reordenar las columnas de mis data frames:

Es una forma correcta aunque muy rígida, manual y bastante propicia a fallos.
relocate()
Como en muchas ocasiones, dplyr viene al rescate de los que nos pasamos horas manipulando, transformando y analizando datos. La función relocate() nos permite reordenar columnas de forma muy intuitiva, flexible y controlada. Y todo ello dentro de nuestros pipelines.
Para empezar, os muestro otra aplicación de across(); en este caso, para convertir todos las columnas de tipo factor a tipo character y luego recuperar el tipo factor para una de las variables (“posicion”). Cuesta más escribir la explicación que programarlo 🙂

Ubicar variable(s) al comienzo del data frame

El primer pipeline coloca la columna “edad” al principio de todas.
El segundo pipeline coloca las columnas “edad” y “peso.kg.” al principio de todas.
Ubicar variable(s) antes o después de una variable concreta

El primer pipeline coloca la columna “edad” antes de la columna “jugador”.
El segundo pipeline coloca la columna “edad” después de la columna “jugador”.
Ubicar variable(s) después de la última columna

Utilizando la función last_col() como valor del parámetro .after, conseguimos ubicar una variable (“edad”) al final del data frame.
Where()
Podemos utilizar la función where() dentro de relocate() para facilitar la selección de variables.

El primer pipeline coloca todas las columnas de tipo character al comienzo del data frame.
El segundo pipeline coloca todas las columnas de tipo character después de las columnas de tipo numérico.
any.of() y all.of()
Por último, podemos utilizar las funciones any.of() y all.of() dentro de relocate() para facilitar la selección de variables.

Ambos pipelines ubicarán las variables dentro del vector al comienzo del data frame.
La principal diferencia radica en que all.of() lanza un error si cualquiera de las variables en el vector no se encuentra en el data frame. En este caso, la variable “nacionalidad” no existe en players.

Podéis descargar el código utilizado en este enlace.
¡Hasta pronto!
datacy – data driven decisions

